Encoding biases into machine learning models, and in general into the constructs we refer to as AI, is nearly inescapable — but we can sure do better than we have in past years. IBM is hoping that a new database of a million faces more reflective of those in the real world will help.
Facial recognition being relied on for everything from unlocking your phone to your front door, and being used to estimate your mood or likelihood to commit criminal acts — and we may as well admit many of these applications are bunk. But even the good ones often fail simple tests like working adequately with people of certain skin tones or ages.
This is a multi-layered problem, and of course a major part of it is that many developers and creators of these systems fail to think about, let alone audit for, a failure of representation in their data.
That’s something everyone needs to work harder at, but the actual data matters as well. How can you train a computer vision algorithm to work well with all people if there’s no set of data that has all people in it?
Every set will necessarily be limited, but building one that has enough of everyone in it that no one is effectively systematically excluded is a worthwhile goal. And with its new million-image Diversity in Faces (DiF) set, that’s what IBM has attempted to create. As the paper introducing the set reads:
For face recognition to perform as desired – to be both accurate and fair – training data must provide sufficient balance and coverage. The training data sets should be large enough and diverse enough to learn the many ways in which faces inherently differ. The images must reflect the diversity of features in faces we see in the world.
The faces are sourced from a huge 100-million-image dataset (Flickr Creative Commons), through which another machine learning system prowled and found as many faces as it could. These were then isolated and cropped, and that’s when the real work started.
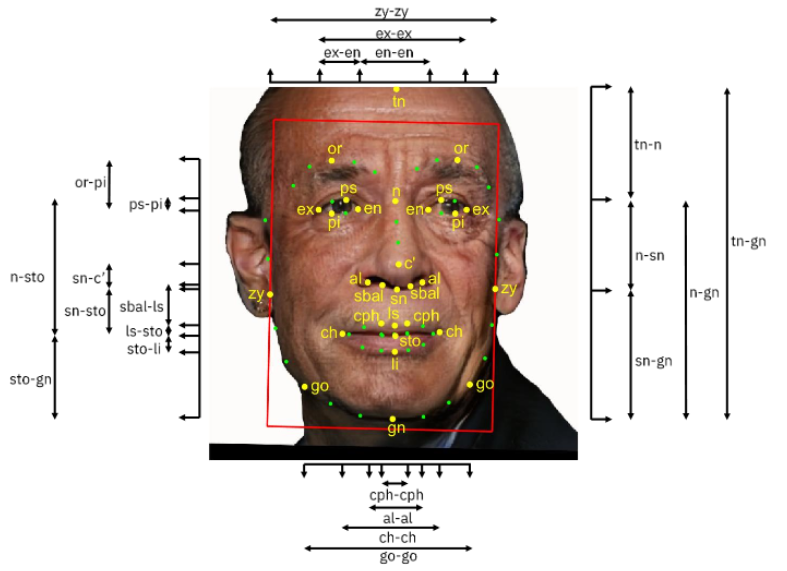
These sets are meant to be ingested by other machine learning algorithms, so they need to be both diverse and accurately labeled. So the DiF set has a million faces, and each one is accompanied by metadata describing things like the distance between the eyes, the size of the forehead, and all that. All these measurements together create the “faceprint” that a system would use to, for example, match one image to another of the same person.
But any given set of those measurements may or may not be good for identifying people, or accurate for a certain ethnic group, or what have you. So the IBM team put together a revised set that not only includes simple things like distances between features, but how those measures relate to one another, for example how the ratio of this area above the eyes to that area below the nose. Skin color, as well as contrast and types of coloration, are also included.
In a move that is long overdue, gender in the set is detected and encoded according to a spectrum, not a binary. As gender is itself nonbinary, it makes sense to represent it as any fraction between 0 and 1. So what you really have is a metric describing how individuals present on a scale from feminine to masculine.
Age is also automatically estimated, but for these two last values a sort of “reality check” is also included in the form of a “subjective annotation” field in which people were asked to label faces male or female and guess at age. Here there may be bias re-encoded, as sourcing from humans tends to introduce it. All these make for a considerably broader set of measurements than any other publicly available facial recognition training set.
You may wonder why race or ethnicity isn’t a category — IBM’s John R. Smith, who led the creation of the set, explained in an email to me:
Ethnicity and race are often used interchangeably, although the first is more related to culture and the second is related to biology. The boundaries within either are not distinct, and labeling is highly subjective and noisy as found in prior work. Instead, we chose to focus on coding schemes that could be determined reliably and have some kind of continuous scale that could feed diversity analysis. We may return to some of these subjective categories.
Even with a million faces, however, there’s no guarantee that this set is adequately representative — that enough of all groups and sub-sets are present to prevent bias. In fact, Smith seems sure it isn’t, which is really the only logical position.
We could not ensure this in this first version of the data set. But, it is the goal. First, we need to figure out the dimensions for diversity. We do that by starting with data and coding schemes as in this release. Then we iterate. Hopefully, we bring along the larger research community and industry in the process.
In other words, it’s a work in progress. But so is all of science, and despite the frequent missteps and broken promises, facial recognition is inarguably a technology we will all be engaging with in the future, whether we like it or not.
Any AI system is only as good as the data on which it’s built, so improvements to the data will trickle down for a long time. Like any other set DiF will likely go through iterations addressing shortcomings, adding more content, and integrating suggestions or requests from researchers using it. You can request access here.






from TechCrunch https://tcrn.ch/2FZNNZE
via IFTTT
Comments
Post a Comment